
静态批处理 & 动态批处理 & GPU Instancing
Intro
我们知道,在传统的渲染管线中,为了渲染一个物体,CPU需要向GPU发送一个DrawCall命令.
比如下面这段代码:
glDrawElements(GL_TRIANGLES, indices->size(), GL_UNSIGNED_INT, 0); |
而在下达DarwCall命令之前,CPU还需要设置好渲染状态,绑定顶点数据,绑定纹理,设置材质等等.比如这样:
glBindVertexArray(VAO); // 设置VAO |
值得注意的是,设置各种参数的操作费用不低,DrawCall也是一个非常费的操作(虽然现代图形API已经做了很多相应的优化).
这就出现了一个问题,看下面这个场景:

在这个场景中,各种各样的物体十分之多,如果每个物体都需要发送一次DrawCall命令的话,那么帧数将十分难看.
那么游戏中都用了哪些技术来解决这一问题呢?
Batch & DrawCall
对于上面博德之门3的场景,我们可以假设如果不做任何优化按某一顺序绘制场景中所有Mesh,伪代码如下:
// 设置城墙墩子1Mesh各种参数 |
我们发现,其实这个场景中有很多相同的Mesh,比如城墙上的墩子.

这些墩子拥有相同的Mesh,纹理,材质,shader.很容易就会发现,我们可以将拥有相同材质等属性的Mesh在同一个地方进行绘制,这样就可以减少设置各种参数了.
// 设置城墙墩子1Mesh各种参数 |
这样我们就减小了设置参数的开销,而这就是Batching的思路和原理,即:
通过合并相同数据,减少状态切换和DrawCall的数量,从而提高渲染效率.
聪明的读者肯定发现了,这里并没有减少DrawCall.别急,那是下文的内容.
Static Batching
回看上文的伪代码:
// 设置城墙墩子1Mesh各种参数 |
自然而然就会想到,是否可以将城墙墩子1和2打包成一个Mesh,这样就可以将两个DrawCall合并为一个DrawCall了.这就是静态合批的思路.
所以我们进化我们的伪代码:
// 设置城墙墩子1Mesh各种参数 |
太棒了,这样我们又成功减少了DrawCall的数量,提升了性能(因为合并Mesh操作比DrawCall要快)
使用条件
在Unity中,启动静态合批的条件如下:
- 静态合批物体材质球相同
使用方法
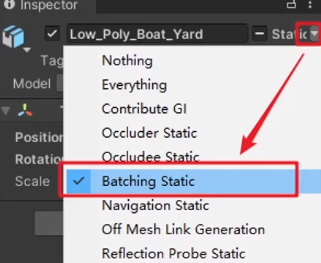
Unity开启静态合批方法如下:
标记物体为Batching Static
优缺点
优点:
- 减少了状态切换和DrawCall的数量,从而提高渲染效率.
缺点:
- 静态合批物体不能移动,旋转等.
- 占用更多内存,因为合并Mesh需要更多的内存.
Dynamic Batching
静态合批最大问题在于,它不能动态改变物体的属性.那如何减少场景中动态的物体的DrawCall呢?
既然在GPU段无法做到改变物体位置,那么是否可以在CPU端将各个物体的位置计算好后再传入GPU呢?答案是可以,这就是动态合批的思路.
动态合批的原理如下:
- 场景绘制前,将所有同一材质物体的顶点信息变化到世界空间中(这样就实现了物体位置的变化)
- DrawCall
当然问题也十分明显:
- CPU承担了GPU的计算任务,导致CPU压力增加.
- shader中不能直接使用Vertex position等属性.
因此动态合批只适合对一些小模型进行合批.
Unity也对动态合批做出了限制:
- 进行Dynamic batching的模型最高能有900个顶点属性
- 如果使用了Vertex position等属性,能够进行Dynamic batching的模型最多只能够有300个顶点
而使用动态合批本身也有一些条件:
- GameObject之间如果有镜像变换不能进行合批(感兴趣读者可以结合原理自行推导)
- 使用Multi-pass Shader的物体会禁用Dynamic batching,因为Multi-pass Shader通常会导致一个物体要连续绘制多次,并切换渲染状态。这会打破其跟其他物体进行Dynamic batching的机会
- 材质相同
- 物体的lightMap指向位置相同
使用方法
在Unity中,开启动态合批方法如下:
- built-in Render Pipeline:
- 打开Project Setting -> Graphics -> Batching -> Dynamic Batching
- URP:
- UniversalRenderPipelineAsset -> Advanced -> Dynamic Batcheing
问题
在Unity中,动态合批功能是默认关闭的,这是为什么呢?
原因是打开动态合批,CPU端的压力会增加,由于CPU不擅长并行操作,所以当CPU增加的消耗大于降低DrawCall的收益时,开启动态合批反而会降低性能.
优缺点
优点:
- 减少DrawCall的数量,提升渲染效率.
- 物体可以移动,旋转等.
- 内存占用少于静态合批
缺点:
- 增加CPU负担
GPU Instancing
看下面这张截图:

场景中有大量的草.读者马上想到可以使用静态合批的方法来增加性能,但问题在于:
- 草数量太大了,消耗的内存也十分恐怖.
- 草往往需要随风而动,不然会十分呆板,静态合批做不到,对动态合批量又太大了
因此对于这种物体,我们需要一种更好的方式来进行绘制.
GPU Instancing的思路是: 我只获取一次数据,然后渲染时渲染多个物体.
那如何解决每个个体的个性化呢?
答案是通过一个InstanceID来区分每个个体.每个个体通过InstanceID来获取自己的属性,比如位置,颜色,UV等.这样就可以做到一个DrawCall渲染多个物体.
opengl提供了三个函数来实现GPU Instancing:
void glDrawArraysInanced(GLenum mode, GLint first, GLsizei count, Glsizei primCount);//无索引的顶点网格集多实例渲染 |
- mode: 绘制模式,一般为GL_TRIANGLES
- first: 第一个顶点的索引
- count: 顶点数量
- primCount: 实例数量
使用条件
在Unity中,使用GPU Instancing的条件如下:
- 材质shader支持Instancing(如何编写支持Instancing的Shader,请参考相关文档)
使用方法
在Unity中,针对单个材质开启 Enable Instancing 选项即可.
优缺点
优点:
- 减少DrawCall的数量,提升渲染效率.
- 物体有个性化
缺点:
- 不支持skinned mesh renderer
- 不支持缩放为负值
- 代码动态改变材质变量后不算同一个材质,但可以通过将颜色变化等变量加入常量缓冲器中实现
- 受限于常量缓冲区在不同设备上的大小的上限,同批的个数可能不同
- 只支持一盏实时光,要要在多个光源的情况下使用实例化,只能切换到延迟渲染路径
SRP Batcher
SRP Batcher是Unity的新功能,可以合批相同着色器变体的多种材质在场景中的CPU渲染速度.
使用条件
在unity中,使用SRP Batcher的条件如下:
- SRP管线
- unity版本5.6及以上
使用方法
在Unity中,开启SRP Batcher的方法如下:
- UniversalRenderPipelineAsset -> Advanced -> SRP Batcher
优先级顺序
SRP Batcher > Static Batching > GPU Instancing > Dynamic Batching
总结
| 静态 | 动态 | GPU Instancing | SRP Batcher | |
|---|---|---|---|---|
| 优点 | 限制少 | 自动 | 性能优秀 | 多材质加速 |
| 缺点 | 增加包体大小,增加运行时内存消耗 | 增加CPU消耗,限制多 | 限制多 | 只能用于SRP |
| 适用情景 | 静态场景,不适合大量重复物体 | 小物体,特效 | 大量重复物体 | 较为广泛 |
 wechat
wechat alipay
alipay