
NeRF介绍
NeRF介绍
前言
NeRF(Nerual Radiance Field):神经辐射场,是在2020年被提出的一种三维重建技术。由于其对比传统三维重建技术来说有简单快速且效果好的优势,尤其是解决了传统三维重建难以处理的反射表面和烟雾等半透明物体,以至于迅速爆火甚至“出圈”。
三维重建
我们经常会听到“渲染”一词,这是一个将计算机中存储的各种数据(Mesh,材质,光照等)通过一定的流程从而得到一张图片。而三维重建可以认为是这一过程的逆过程,即通过已有的图片,来还原一个三维的场景。
传统的三维重建技术一般有四个步骤:
1. SfM(运动恢复结构)
该步骤接受图像和摄像机内外参数作为输入,输出一个三维的稀疏点云
2. MVS(多视立体视觉)
该步骤将前一步的稀疏点云进行稠密化,进而输出稠密的三维点云
3. 表面重建
根据三维点云计算出三角网格
4. 纹理重建
通过输入图像为mesh计算出纹理
传统的三维重建很常常会出现模型有空洞和不正确的问题,并且需要很多的数据量,而且其中的算法颇为复杂。
NeRF OverView
NeRF对于传统三维重建技术最大的不同点在于,通过构建一个神经辐射场来隐式地表达了场景,而跳过了传统几何方法中的很多很难的步骤。这是赐予了NeRF无数优点,但也造成了NeRF的最大缺点—由于是隐式表达场景,导致难以“原生”地修改场景,并且一个神经辐射场只能存储一个场景,泛化性差。
NeRF流程:
1. 输入照片
2. 训练NeRF
3. 渲染新图片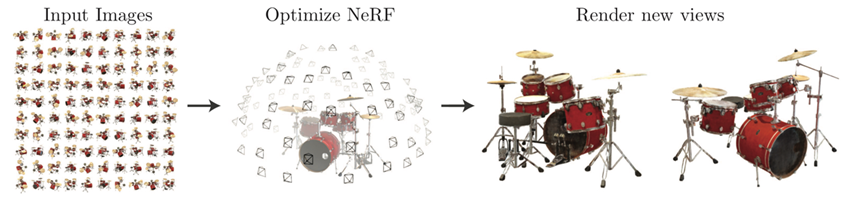
NeRF第三步渲染主要流程如下:
1. 前处理过程,计算采样点位姿(5D向量)
2. 向NeRF中输入采样点,输出采样点RGBA(此处A其实更准确意思是密度)的四维向量
3. 后处理过程,根据一个像素的一系采样点信息渲染出最终的图片
对于不熟悉计算机图形学或者体渲染的读者来说,这里可能会有点难以理解。为了方便后续理解,这里可以认为NeRF存储的是空间中一些稀疏的点,这些点存储了我们渲染图片所需要的信息,通过神经网络,NeRF又将这些离散的点变成连续的点。
前处理过程
一个采样点的位姿记录了一个5维向量—位置(x,y,z)和方向(极坐标)。
接下来计算这个向量。
首先需要由像素点反推摄像机到该点的射线。
通过像素点的坐标(u,v)和摄像机的参数,我们可以得到过这像素点的射线。
射线表示为:o + td(o为原点,t为行进距离,d为行进方向)。
然后在这条射线上沿着光线方向采样一系列点(即一系列t)。
在采样的方法中,可以设置一个最小距离和最大距离然后进行均匀采样。但还可以为其加上一些扰动,以带来更好的效果。
神经网络
NeRF接受一个五维向量(位置方向),输出一个四维向量(RGBA)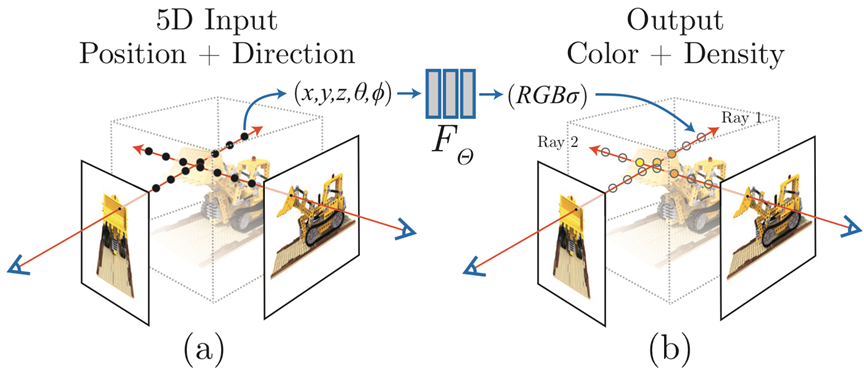
在神经网络模型上,NeRF的结构不算复杂,就是一堆全链接层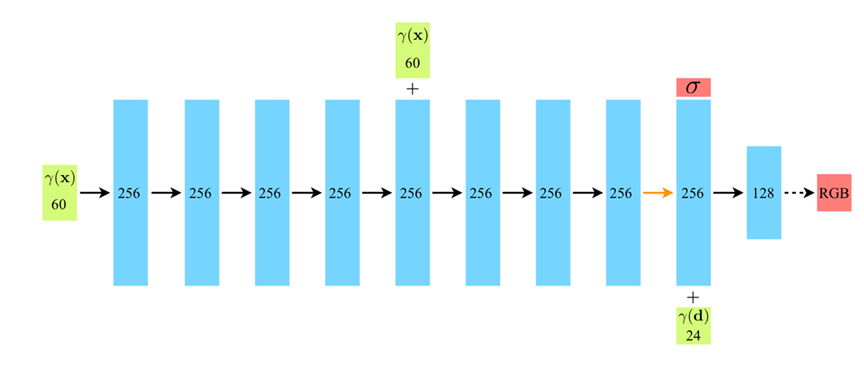

首先向网络中输入三维的位置。
注意到在第5层时,NeRF使用了一个残差结构来解决梯度消失和梯度爆炸的问题。
而在第8层,NeRF输出密度(一维)和另外256维结合二维方向输出为128维的结果。
之所以要在第9层再输入方向,是因为一个采样点位置的密度与其辐照度(颜色)没有关系。
NeRF论文实现中,一个像素需要采样64个点。
但是读者可能发现了,在图中,神经网络并非接受3维向量而是60维向量。这是因为位置编码的关系,而这会在后文中解释。
Volume Render
在进过上一步骤之后,我们获得了着色像素点射线方向的64个采样点,接下来就是通过体渲染计算这个着色点的颜色。
在常规体渲染中,光与Participating Media交互时有以下四个过程:
1. Absorption(吸收)
2. Emission(自发光)
3. In-Scattering(入射光)
4. Out-Scattering(外射光)
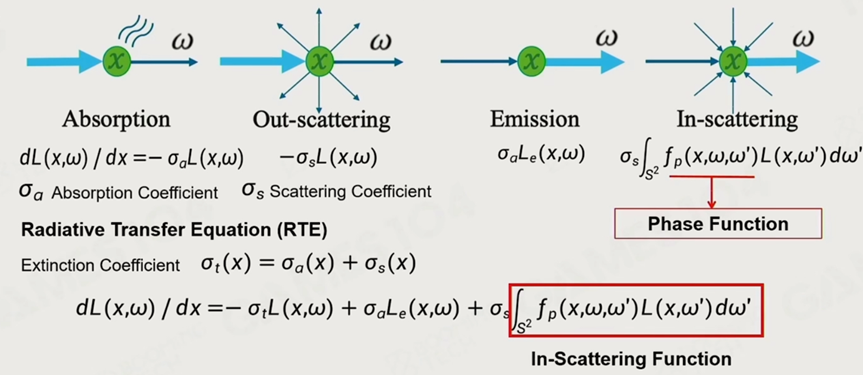
我们使用RTF(Radiative Transfer Fuction)来计算光与“一个”Participating Media交互的结果。
在光线的一条路径中,我们使用VER(Volume Rendering Equation)计算最终结果。而VER实际上就是对RTF的积分。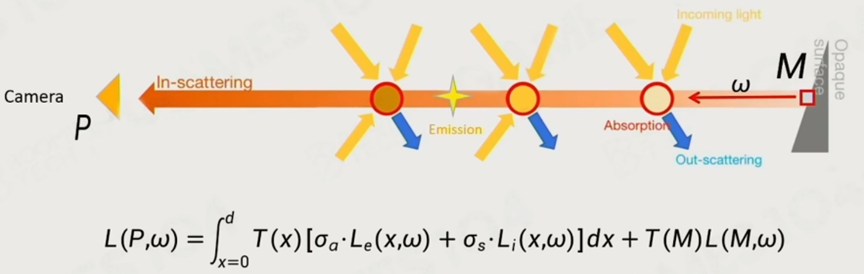
而在NeRF的体渲染中做出了以下假设:
1. 入射光和外射光相互抵消
2. 粒子有密度
NeRF使用下面这个公式进行积分计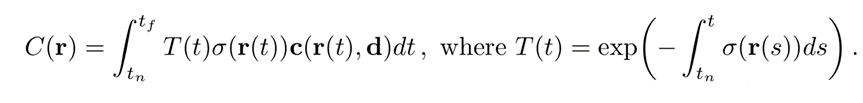
其中:
r(t):光线方程 = o + td。
T(t): 在t点前没有被阻挡的概率
o(t): t点处光线碰击粒子的概率
C(t): 自发光
其中,o(s)和c(t)都由NeRF的输出给出,唯一需要求解的就是T(s)
而T(t)通俗理解就是光线在t点的可见性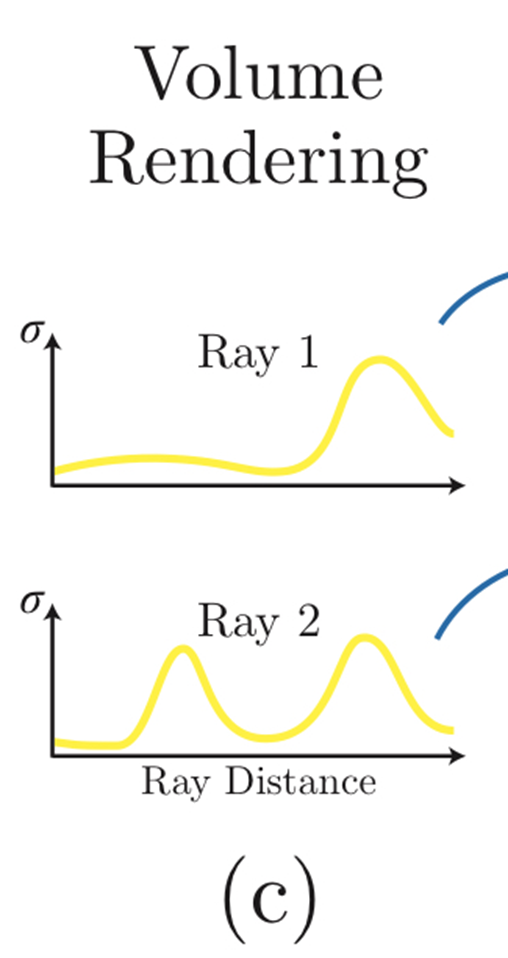
如图,Ray2在抵达第二个波峰前可能就已经不可见,所以事实上计算像素最终颜色时就已经不需要第二个波峰的贡献了。
至此,我们就得到了最终渲染结果的图片。
Loss 函数计算
NeRF的训练使用自监督的方法。
NeRF使用MSE作为Loss函数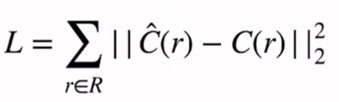
对某一像素计算一遍颜色作为该像素的预测值
Positional Encoding
在前文中,提到过NeRF的输入实际上并不是5维度向量,而远比5维多。这是因为在实际的使用过程中,只使用5维向量会导致结果丢失高频信息。
而解决方法就是使用位置编码。
在方法上,NeRF引入了sin和cos。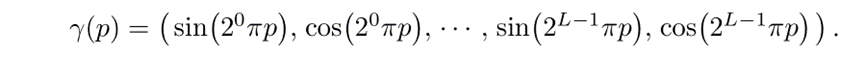
而在论文中,对于(x,y,z)L=10,所以就是3 * 2 * 10 = 60,即我们看到的60维向量的输入。
而对于视角方向,L = 4,就是2 * 2 * 4=16.而之所以图中是24是因为论文中实际上并不是使用极坐标来表示方向而是一个单位向量,就是 3 * 2 * 4 = 24.
这也说明相较于位置坐标,视角方向的重要性也稍小一些。
结语
由于NeRF的特性,使得其在对于静态场景的重建上十分优秀,而其对数据的要求相比传统三维重建技术又少了很多,笔者认为其实很适合大众用来保存一些曾经充满回忆的场景,比如即将离开的寝室等。
参考
B站NeRF详解
[NeRF论文](https://arxiv.org/pdf/2003.08934)
[知乎-NeRF解析](https://zhuanlan.zhihu.com/p/597579341?utm_psn=1796367451891564545)
[知乎-三维重建](https://zhuanlan.zhihu.com/p/674945123?utm_psn=1796367867605815297)
Games104
[B站NeRF介绍](https://b23.tv/HWjdeQa)
[影视飓风](https://b23.tv/lqRK7wc)
 wechat
wechat alipay
alipay