
DDGI介绍
前言
DDGI(Dynamic Diffuse Global Illumination,动态漫反射全局光照).是由Nvida于2019年推出的一种基于Probe,基于RayTracing(光线追踪)的动态漫反射全局光照技术,可以在动态的场景与光照中实时的生成漫反射的全局光照.
全局光照
在实时渲染领域中,实现全局光照意味着实现间接光照,即光线弹射两次或更多次后进入人眼的光照。
在DDGI技术出现的2019年之前,学界在解决全局光照问题时的方法就已经可谓是百花齐放,所以我们先简单回顾一些经典的全局光照的解决方案.
Baked Global Illumination
Baked Global Illumination(烘焙全局光照)或称Lightmap(光照贴图)是一种离线计算全局光照的方法,也是目前游戏中主流的解决方法.
这种方法的基本思路是将场景中的光照信息预先计算并保存为一张光照贴图,然后在渲染时直接读取光照贴图进行渲染.而在计算光照信息时,常常会用到光子映射的技术.
它们的优点是结果细腻,但是缺点是无法处理动态场景或动态光源.
这不由得让我想起了小时玩黑魂3时判断宝箱怪的技巧:
没有影子的宝箱是宝箱怪.
当时以为是刻意设计的我在此刻发出了爽朗的笑声.
因为宝箱怪是会动的,所以烘培光照贴图时没有烘培出宝箱怪的阴影.
Irradiance Probes
Irradiance Probes(辐射探针)技术和Lightmap技术一起构成了当今游戏主流的全局光照解决方案.其中,Lightmap主要负责细腻的静态场景,而Probe则主要动态的物体.一动一静,两者相结合,就是当今大部分游戏的解决方案.
这一方案的思想是通过在场景中布置预计算的探针,存储场景中光照信息,用于渲染时计算光照.而根据需求的不同,在场景中会布置用于计算光照的Light Probe,还有用于计算高频信息的Reflection Probe.
辐射探针存储了在一个球面上全方位方向上的数据,这些数据被映射到纹理内存中.映射方式有立方体贴图,球谐函数,八面体,双抛物面等.在DDGI中,使用了八面体映射.
辐照度探针能为图像渲染提供相当高的质量,尤其当表面靠近探针时,其产生的结果可以相当正确.但是辐照度探针存在以下问题.f
烘培时间长,有时还需要艺术家手动调整Probe以避免漏光等问题
静态,不能应对动态变化
由于是预计算的探针,当场景中的物体,光照发生改变时,探针的信息却依然是未改变前的,这就导致的错误的结果.不过事实上在游戏引擎中也存在着在运行时更新的探针的方法.
光照泄露和阴影泄露
由于在使用探针时并没有考虑可见性的问题,这就会导致表面在在采样附近探针时采样到错误的光照信息,导致光照或者阴影泄露.而在解决这一问题上,工业界更可以说是八仙过海各显神通,在GDC和SIGGRAPH等大会上都有大量的解决方案被提出.
而解决这些问题也是DDGI技术发展的动力之一.
VPL
VPL(Virtual Point Light)是一种实时的计算全局光照的方法。该方法的思想是在场景某些位置创建虚拟的点光源,该点光源的强度来自直接光照,而受这些点光源影响的表面则可以获得近似的间接光,以此来模拟二次弹射的光线.
该方案将循环递归的渲染方程近似为大量点光源这一相对简单问题.
但这也会带来所谓的多光渲染问题(Many-lights Rendering),为了解决这一问题,产生了一系列如IS,Light BVH,Lightcut,ReStIR,ReGIR等技术
生成VPL常常使用一种名为RSM(Reflective Shadow Map)的方法.它使用光源空间下生成的Shadow Map来生成VPL。
RSM
RSM早在2005年就已经被提出.
它的来源基于一个Observation:在使用Shadow Map技术时,通过Light Space的Shadow Map我们可以准确地获得所有第一次被照亮的”点”,那么这些点不就正是次级光源的位置吗?
那么我们就可以根据这些点来生成VPL.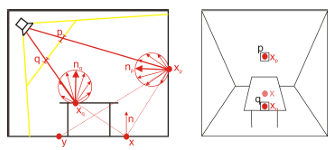
LPV
在此之上的还有LPV(Light Propagation Volumn),它将RSM生成的VPL注入到一张3D Volume 中并向相邻网格增殖出更多VPL.这一技术最早被使用在CryEngine中,并被实装于大名鼎鼎的”显卡危机”里.
LPV的核心思想是:利用一个3D的Grid来存储场景中光源的Radiance,然后迭代几次这个Grid用来模拟光线传播.在着色时就可以使用这个Grid来模拟计算间接光照.
而LPV的这一思想可贵之处在于,它考虑了光线在空间中传播,而这一点可以让其一定程度上模拟2次以上的间接光,这是RSM算法无法做到的.
不过事实上,可以通过对RSM产生的VPL再次进行RSM来模拟两次以上的间接光,但光听描述也可以知道,这肯定不是一个性能优秀的方案.在实际使用RSM时,也几乎只对场景中的光源使用RSM来模拟二次弹射的光线,而不会去模拟更多弹射的光线
SVOGI
SVOGI(Sparse Voxel Octree Global Illumination)是一种使用体素来存储光照信息的全局光照技术.而在数据结构选择上,SVOGI选择了使用八叉树.
在SVOGI中有一个对后续研究很有启发的想法:ConeTracing.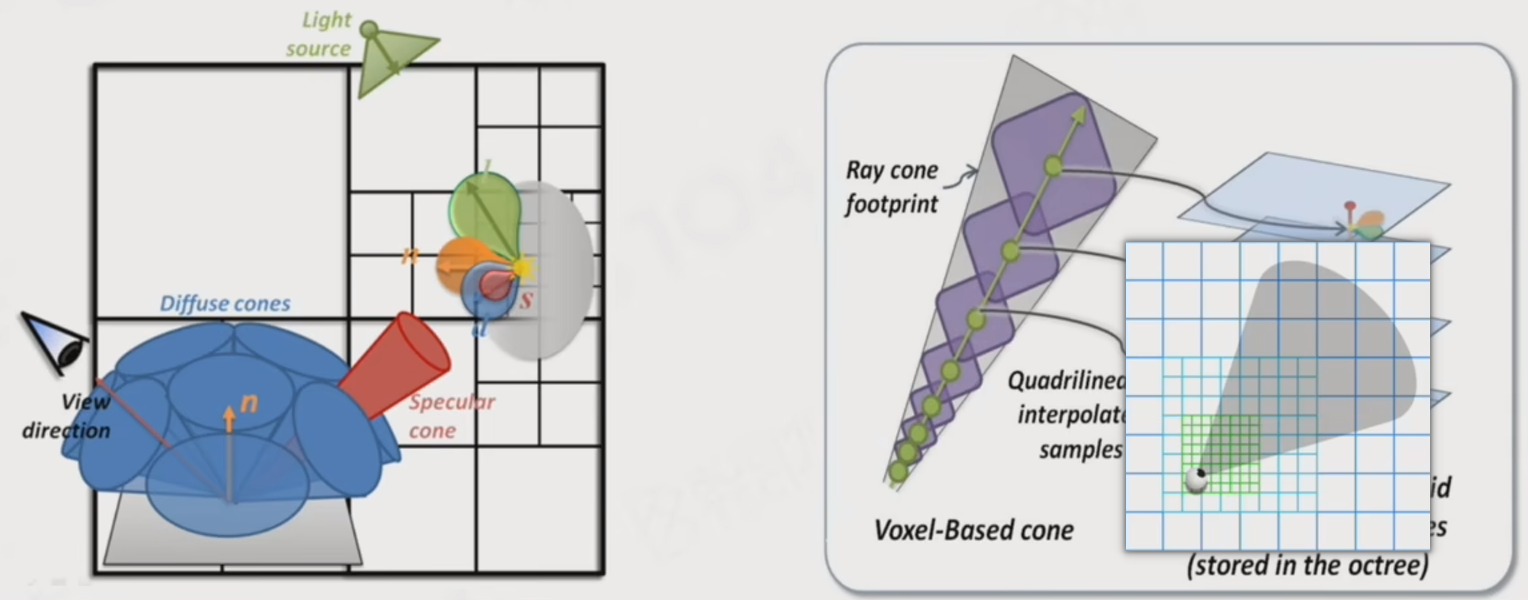
ConeTracing对比RayTracing最大的不同处在于:有厚度.
在单根RayTracing时最大的问题就是:对远处的物体采样不足.
ConeTracing则可以对一整个区域内进行积分.
具体ConeTracing的方法简单说就是:一个step一个step地进行,从近处开始用一个球体或者立方体或者whatever,然后求交,随距离变大.
可以看出Voxel类的数据结构天然就很适合ConeTracing.
VPL总结
VPL方案的一大技术难点是可见性计算的问题,RSM和LPV都没有考虑虚拟点光与物体之间的可见性,所以生成的间接光是没有考虑可见性的.
目前也有用Ray Marching算法来计算可见性,但是显而易见的会带来大量计算量.还有一种方案是ISM(Imperfect Shadow Map),该方案为VPL选择离散的点来近似计算可见性.
可见性会带来可以说是众多全局光照的”一生之敌”之一的问题–Light Leaking.也就是漏光,漏阴影问题.
Voxel GI
Voxel GI(体素全局光照)是一种基于体素的全局光照技术,它将场景稀疏体素化后,使用“Voxel Cone Tracing”体素锥体追踪的方法收敛间接光。
Voxel GI的核心思想是:近处的间接光照更重要,可以进行更精细的采样,远处的间接光照可以进行更粗糙的采样.反映在策略上就是,物体近处使用半径更小的Voxel,远处使用更大的Voxel.这种数据结构被称为ClipMap.
SVOGI将八叉树存储在一张邻接的2D Texture上,而VXGI则存储在ClipMap上.
这一数据结构的变化让VXGI对比SVOGI有以下优势:
- GPU Friendly
- 更加清晰(SVOGI的数据结构挺复杂的)
Voxel GId的步骤如下:
- 使用RSM生成VPL
- 将VPL注入到体素中
- 使用Cone Tracing进行Shading
VXGI也存在一些问题:
- 渲染半透明物体会出现不正确的遮挡关系
- 当遮挡物比Voxel小时会Light Leaking
SVOGI (sparse voxel octree GI)
VXGI (voxel GI)
Screen Space GI
SSGI最早由大名鼎鼎的寒霜引擎在2015年提出.它的思想其实非常简单:渲染好的像素点本身就可以作为一个VPL.
SSGI的过程如下:
- 在着色点发射一些反射的光线
- RayMarching求交
- 用交点屏幕空间的颜色作为间接光照
而在RayMarching的过程中,为了提高速度,使用到了一种名为Hierachical Tracing的技术.
Hireachical技术基于一张mip map的深度图,被称为HZB(High Z-buffer).
在HZB中,上层的Z-Buffer值一定低于下层的Z-Buffer值.
而Hierarchical Tracing巧妙的利用了这一特性:在进行Ray Marching时,如果ray在z plane之上,则ray Marching的步长则会等比例(与mip map缩放比例相同)提高,之下则减少,以此来减少ray Marching的计算量.
SSGI另一个巧妙之处在于采样点的Reuse.
相邻像素的采样点可以重用,从而减少计算量.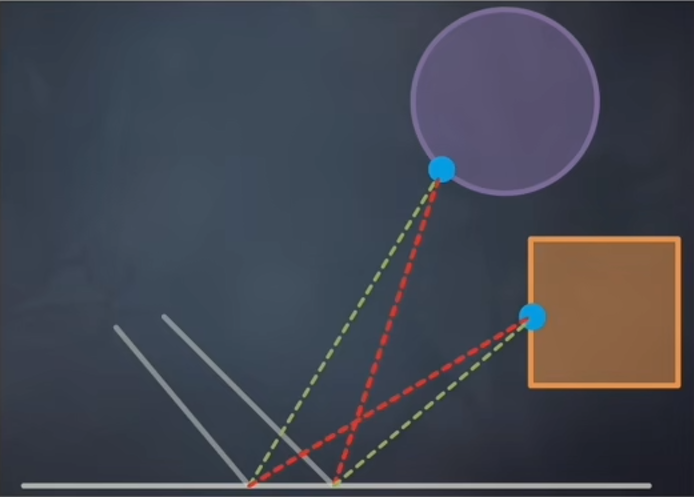
SSGI的优点是:
- 能很快计算glossy和specular材质
- 质量好
- 支持动态物体
缺点也很明显:
- 屏幕外的东西无法计算
- 当相邻像素点距离远时会出现错误
笔者在写这一部分时,写一个点就会发现,Lumen中有相同的思想或Lumen解决了SSGI的这个问题.嗯,SSGI真棒
Denoised Ray Tracing
说到全局光照的最终解决方案与终极武器是什么,可以毫不犹豫地说:路径追踪.
路径追踪算法的核心思想之一是使用蒙特卡洛积分计算计算渲染方程.而这一方法的问题与难度在于采样.在实际使用路径追踪时也需要大量进行采样,这是非常高的性能要求.
那么,在支持硬件光追的RTX系列显卡中,每帧可以做到多少ssp呢–1ssp.而作为对比参考,我们认为,渲染一个质量优秀的室外场景需要100+ssp,而渲染一个室内场景需要500+ssp.
而即使是在笔者写文章的2024年,当今最强4090也只能做到2ssp.
在几个数量级的巨大差距下,如何去优化采样策略带来的优化也显得微不足道.
所以在实时路径追踪中,最重要的问题在于如何增加ssp或者说降噪.而这一问题来到实时渲染领域时,几乎只剩下了唯一一种解法:时间累积.
和TAA的做法相同,在屏幕空间通过运动向量累计当前帧与历史帧的结果以此来实现降噪.
但问题也非常显而易见:当像素是”新”的没有历史帧时会造成噪点;当像素的历史帧数据对当前帧来说已经是错误时(比如光线发生变化)会带来错误的结果.
但路径追踪带来的效果也是惊人的,在CyberPunk 2077中,已经可以在支持的显卡上开启路径追踪.读者可以在游戏中实际进行体验.笔者的电脑在开启DLSS的情况下只能跑到10多帧,噪点也是随处可见,但总体画面依然可以说是十分惊艳的.
一些其他的GI
Lumen:一个集光线追踪,表面缓存,SS Radiance Cache,Voxel GI,SSGI,SS Probe,SDF等一系列技术的GI解决方案.
NN Probe GI: 一种利用神经网络快速收敛probe的方案.
RTX GI: 由Nvida推出的一系列基于RTX的GI技术.(包括DDGI,NRC,SHaRC)
光线追踪
DDGI的一大基础是光线追踪。
在传统的光栅化流程中,像素的着色过程发生在Fragment Shader中,在此过程中一般只能得到部分光源与当前着色点的信息,而无法直接得到场景的遮挡关系以及光线传输过程,所以难以计算软阴影和间接光照等.
而光线追踪则是一个与光栅化完全不同的流程.它是从相机出发,在每个像素点向场景投射光线,光线会在场景中进行反射与折射直到到达终止条件,在此过程中进行了着色.相比起光栅化流程,光线追踪可以很容易地计算阴影,并且能够自然而然地计算出软阴影,间接光照,环境光遮蔽等等.但是缺点也很明显,就是性能消耗大.
而在光线追踪中,最为耗时的计算是求解光线与物体表面交点的过程.
在新一代的RTX显卡中,增加了光追核心,能够支持硬件光追,而其优化的正是光线与表面求交这一运算.
RTX 光线追踪
Nvdia 在2018年推出了RTX(Ray Tracing X)标准。同期微软配合实现了符合该标准的API,即DXR(DirectX RayTracing),至此光线追踪可使用于这套API运行于支持的显卡上。
2019年,Epic 在Unreal中实现了相对完整的DXR管线
2020年,Khronos在Vulkan上实现了一套符合RTX标准的API
RTX光追的核心流程大致如图所示: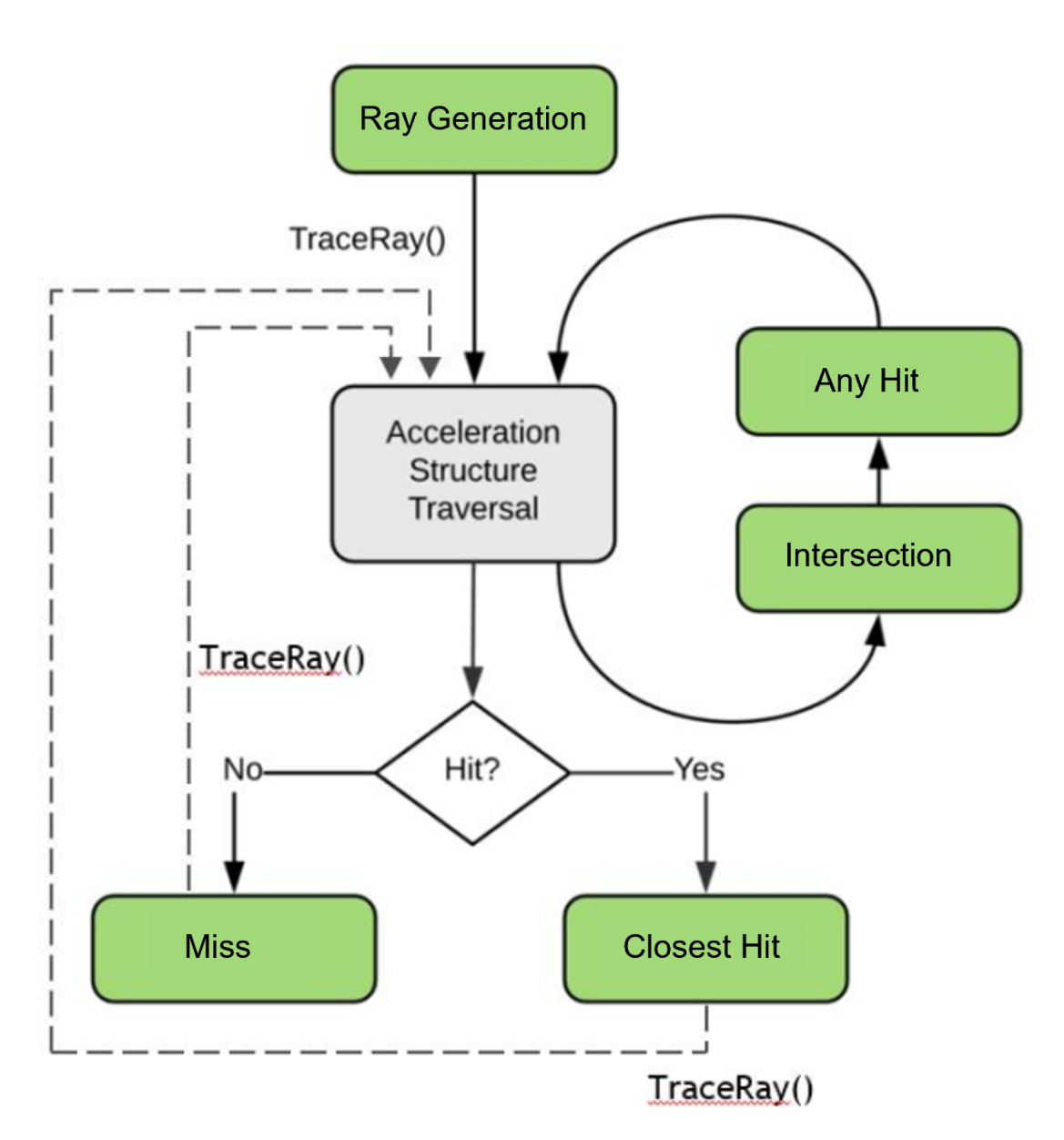
关于具体DXR的更多具体内容,这里不再多说明(不会).
但是可以看一下以下DXR关系提供的一些shader.笔者在自己写过路径追踪后,再看这些名字感觉还是非常的亲切.
RGS(Ray Generation Shader)用于发射光线。必须的。
IS(Intersection Shader)用于自定义加速结构基元的求交规则。可选的。
AHS(Any Hit Shader)射线与加速结构有任一交点时被触发。可选的。
CHS(Closest Hit Shader)最近的有效交点才触发,每条射线最多触发一次。可选的。
MS(Miss Shader)光线没有与场景相交时触发。必须的。
DDGI Overview
如前文所言,DDGI是一个基于Probe的,基于RayTracing的动态漫反射全局光照技术.
我们先回顾传统Irradiance Probe的三大缺陷:
- 静态,不能应对动态变化
- 光照泄露和阴影泄露
- 烘培时间长,有时还需要艺术家手动调整Probe以避免漏光等问题
对于DDGI而言,首先通过在探针中存储可见性信息以防止光线和阴影泄露(但事实上还是会有一点,不过可以优化).
然后,DDGI通过实时更新秒杀了另外两个问题,而做到实时更新的关键算法就是–光线追踪.
DDGI 更进一步
DDGI Probe
DDGI Probe 存储了一个位置的三个关于方向的函数
1.E(w):Probe从w方向的半球面接收到的Irradiance.
2.r(w):Probe从w方向看到的最近物体与Probe的距离.(存储半球面上的均值)
3.r^2(w):Probe从w方向看到的最近物体的平方距离.(存储半球面上的均值)
DDGI Probe会将这些信息存入一个纹理贴图中.不过实际上,Probe并不会负责存储纹理,而是由DDGI Volume来存储和管理,Probe只有一个序号.
由于Probe中存储的是球面信息,需要将球面映射到二维平面再存储到纹理贴图中.DDGI采用的是八面体映射的方法.该方法将球面映射到八面体后再映射到正方形来存储.
相比于传统的Probe,DDGI Probe 多存储了r(w)和r^2(w)两个函数,用于解决Light Leaking 问题.
如果读者熟悉用于计算软阴影的VSM算法,或许会对着两个函数感到熟悉:VSM中使用深度和深度平方的均值进行切比雪夫测试用以估计物体在阴影处的概率以减少采样.在DDGI中,会采用与之类似的算法.
DDGI Volume
DDGI Volume 是一个体积数据结构,是一组DDGI Probe的集合,用于存储和管理Probe与其中的信息.DDGI Volume会将其中的所有Probe纹理打包成一个大的图集来进行存储.
DDGI 渲染
对于Volume内的任意一个着色点,首先找到这个着色点周围的8个Probe.通过采样这8个Probe上的Irradiance,并按照一定的权重进行混合,即可得到着色点Irradiance,然后进行渲染.
先写出反射方程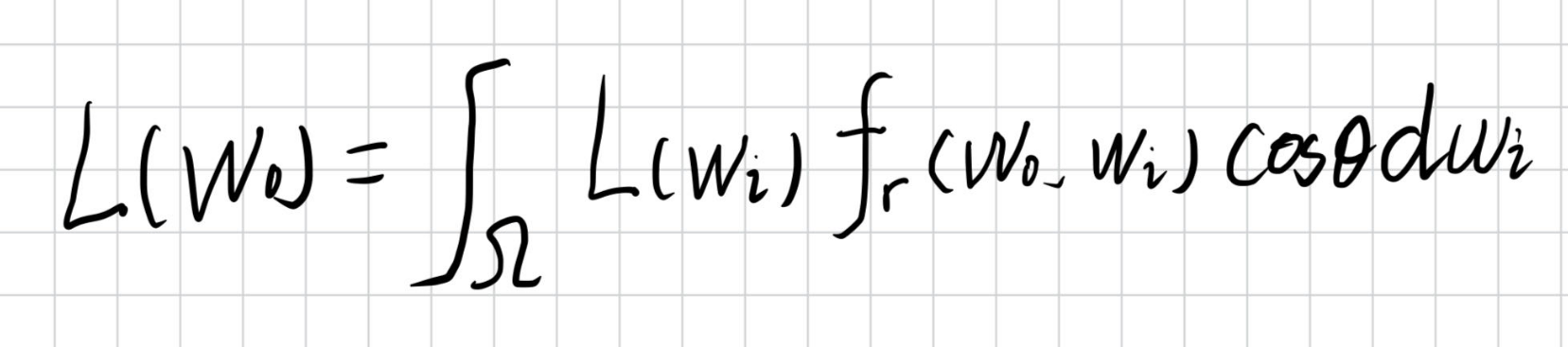
在Cook-Torrance BRDF中,由于DDGI计算的是漫反射项,我们将其提出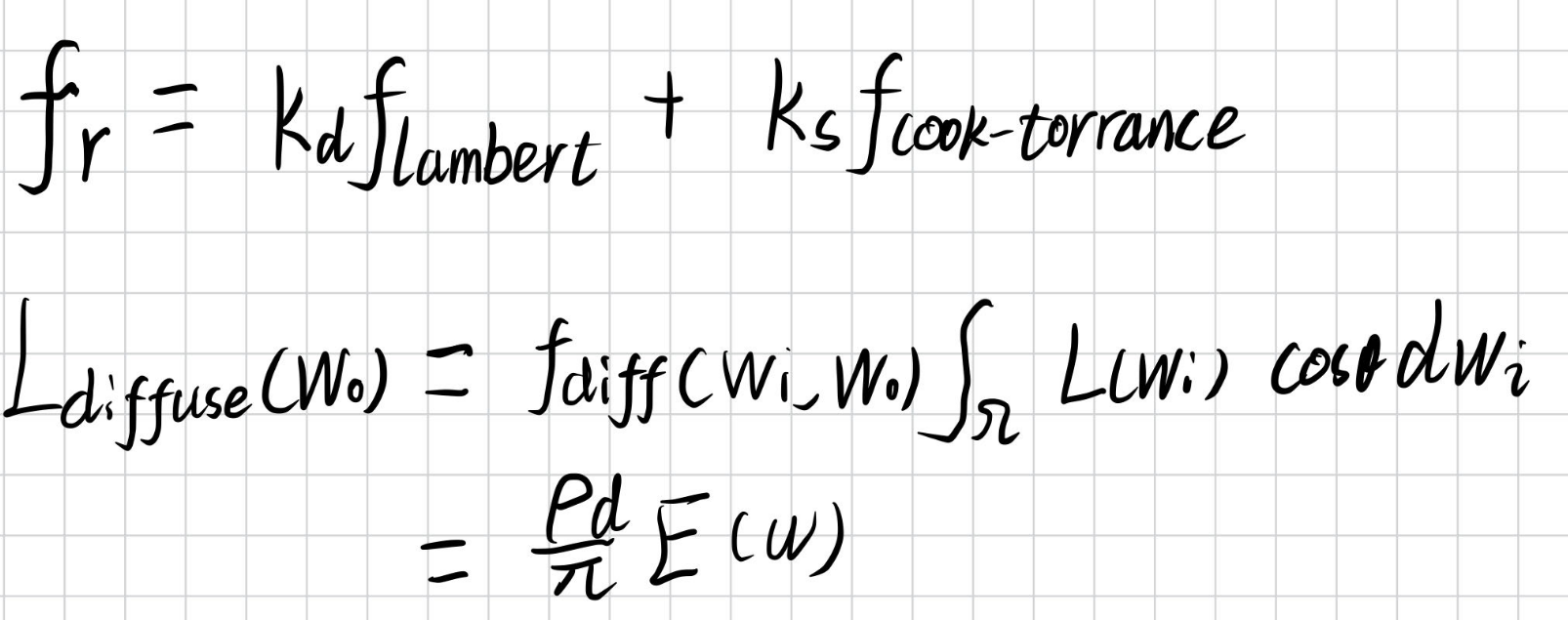
注意到公式后半部分”就是”E(w),即Probe中存储的信息.其中w为着色点表面法线.
而公式后半部分的值则由周围八个Probe中存储的E(w)的加权平均来近似.
在计算Probe权重时,DDGI使用三个权重系数的乘积:三线性插值系数,方向系数,切比雪夫测试系数.对应了三种情况:
- 三线性插值:用于解决Probe的位置不准确的问题.
- 方向系数:用于解决Probe的方向不准确的问题.
- 切比雪夫测试:用于解决Probe的可见性不准确的问题.
最后再进行归一化.
下图展示了不同权重系数的影响:
接下来详细说明三个系数的计算
三线性插值
首先,让我们先来理解双线性插值.如图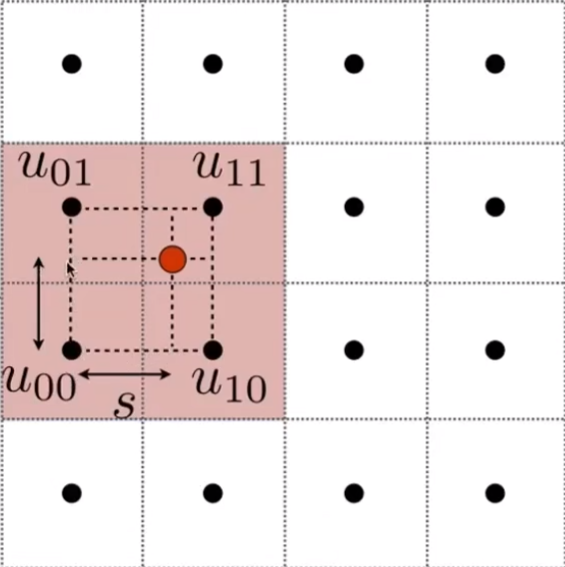
其中红点是我们需要插值的点,周围四个点是采样点.
然后我们定义线性插值 lerp(x,v0,v1) = v0 + x(v1-v0)
然后我们对两条对边进行线性插值,得到两个点.这里对水平插值,如图.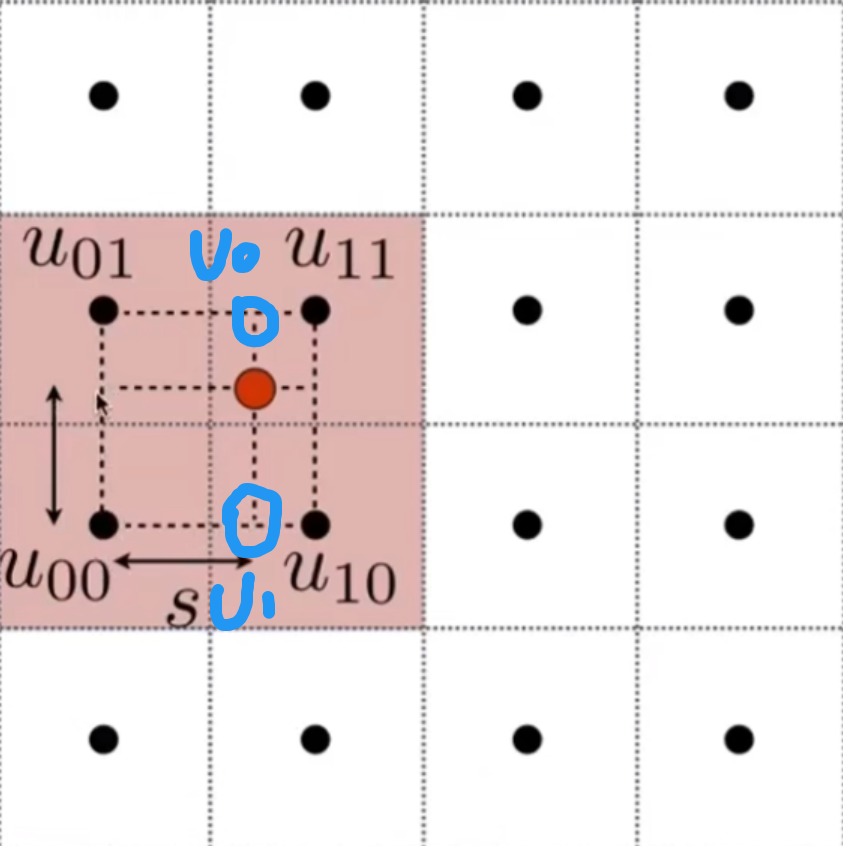
最后对竖直方向插值即可得到最终结果.
而三线性插值只是比双线性插值多一维度而已,原理相同.
方向系数
在计算光照时,常常会使用到光源方向与表面法线夹角的余弦来判断光照是否在表面的背面.但由于DDGI是使用离散的Probe来近似表面的irradiance,所以即使在背面的Probe也需要考虑贡献,比如这种情况: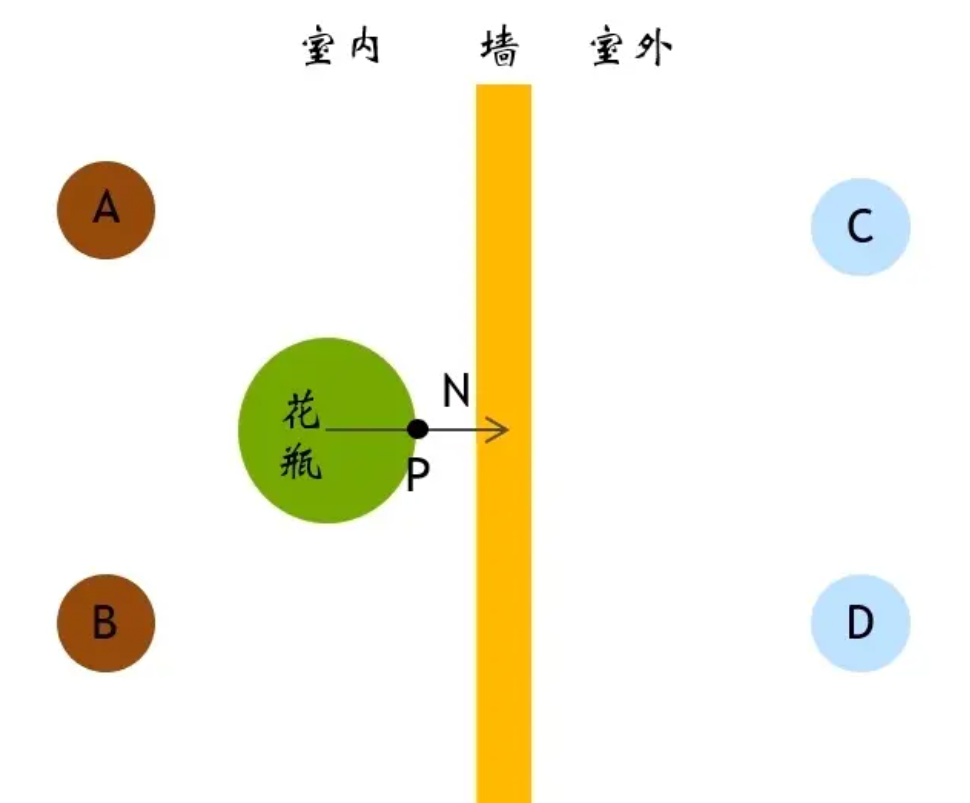
DDGI使用以下公式计算方向系数: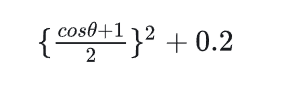
切比雪夫测试
DDGI使用切比雪夫测试来解决Probe的可见性不准确的问题.
首先如图: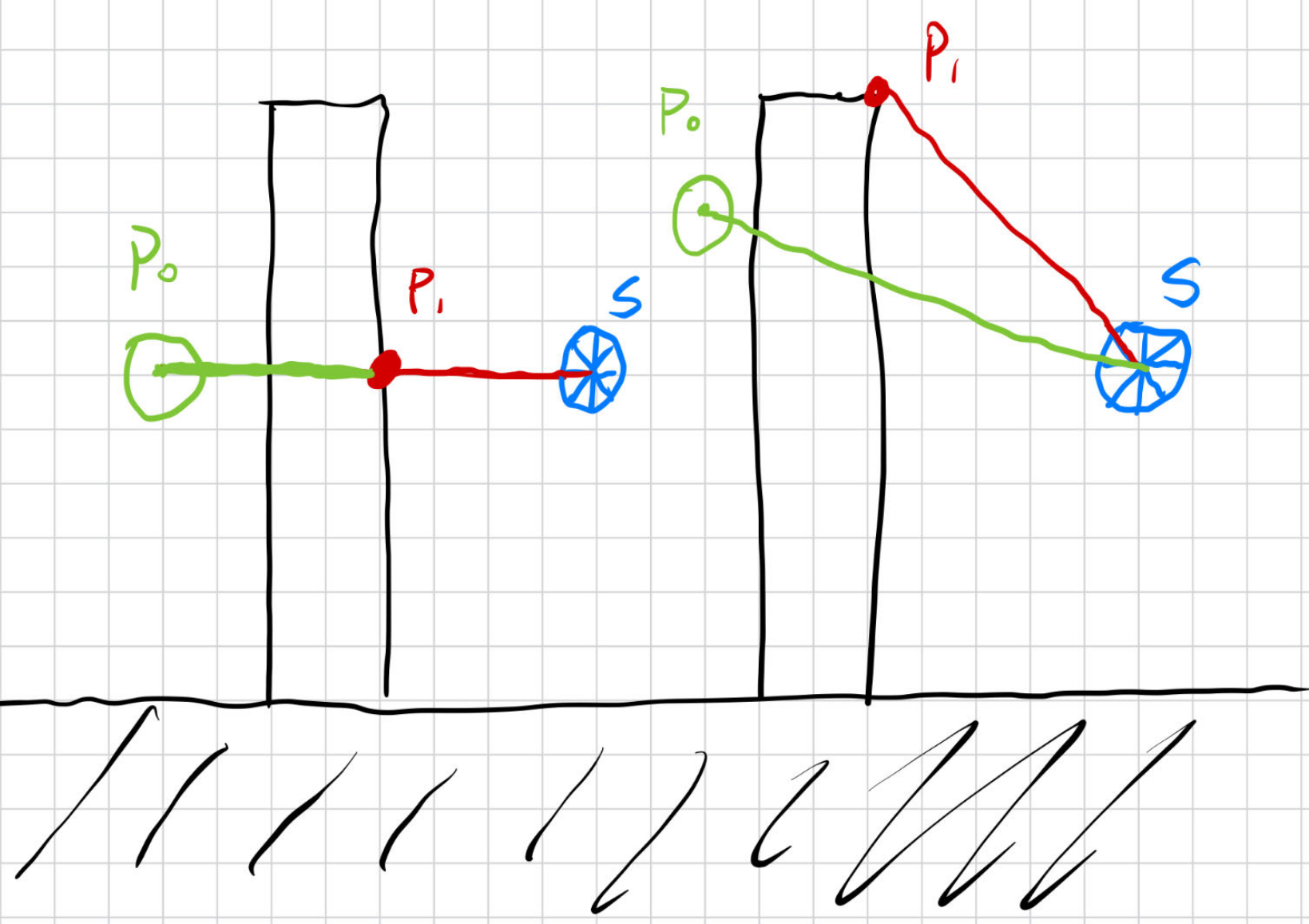
po是着色点的位置,s点是Probe.现在需要判断Probe是否对p0有贡献.
很自然的可以想到,可以通过判断Probe与p0的距离是否小于Probe与po的距离来判断.
对于左边的理想情况来说是确实是正确的.
但是由于Probe存储的信息是离散的,更为常见的反而是右图的情况,而此时仅通过距离来进行判断就很有可能出现错误.
所以可见性问题不能只简单的比大小,更多的是一个概率问题.所以DDGI引入了切比雪夫不等式来进行概率的估计.
首先介绍切比雪夫不等式: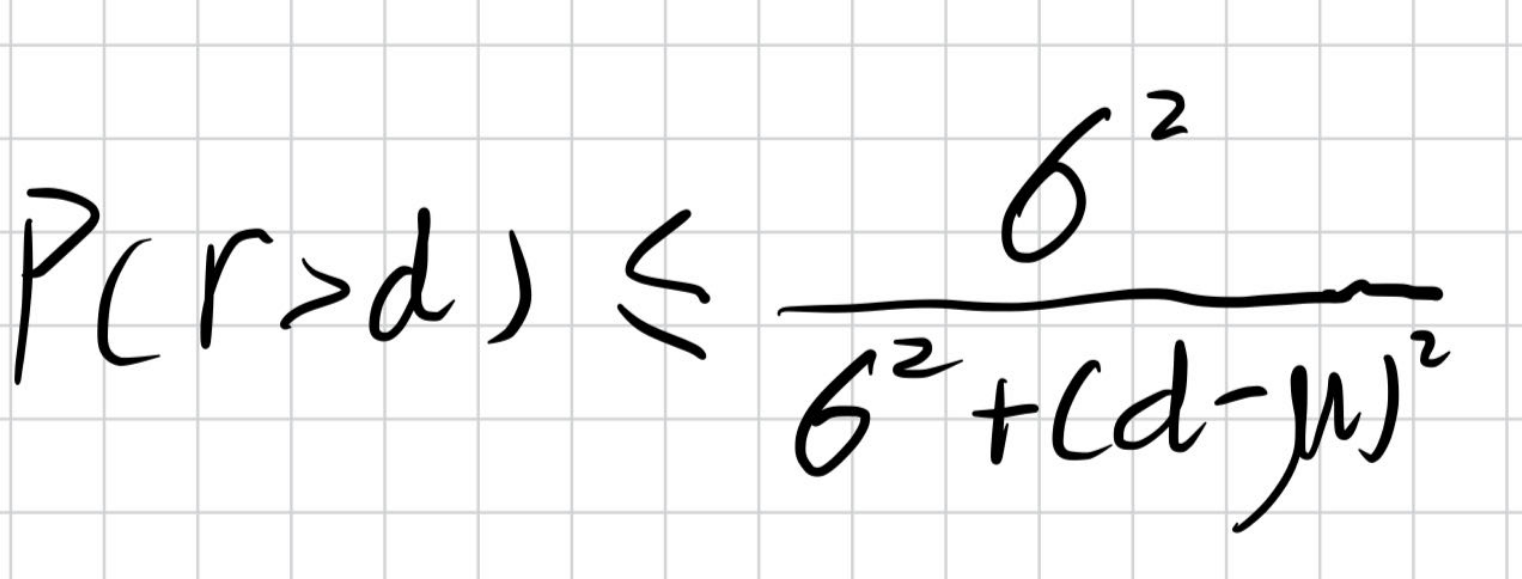
其中r是Probe向着色点方向看到的最近物体的距离.d是Probe到着色点的距离.
我们在使用切比雪夫不等式时做出了一个大胆的假设:假设总是能取到上限.
然后切比雪夫不等式就进化为了切比雪夫等式.
当d大于期望时,直接使用计算结果,当d小于期望时,我们return 1;
这虽然听起来挺扯,但实际上却也是一种很好的近似方法.
而我们在Probe中存储了r(w)和r^2(w)两个函数,就可以用来计算切比雪夫等式了.
生成与更新 DDGI Volume
回顾在Probe中存储的数据:
1.E(w):Probe从w方向的半球面接收到的Irradiance.
2.r(w):Probe从w方向看到的最近物体与Probe的距离.(存储半球面上的均值)
3.r^2(w):Probe从w方向看到的最近物体的平方距离.(存储半球面上的均值)
生成和更新Probe就是计算上述三个函数.
主要有两个步骤:
- RayTracing 计算Probe Radiance & Distance
- Probe Blend
接下来详细讲解计算过程.
Probe 分布
在DDGI论文中,给出了两种Probe的分布方案:
1.Grid:均匀分布
2.Cascaded:层级分布
关于Probe分布的问题这里不过多讨论.
发射光线
对于每一个Probe,使用斐波那契螺旋采样算法向球面上发射光线.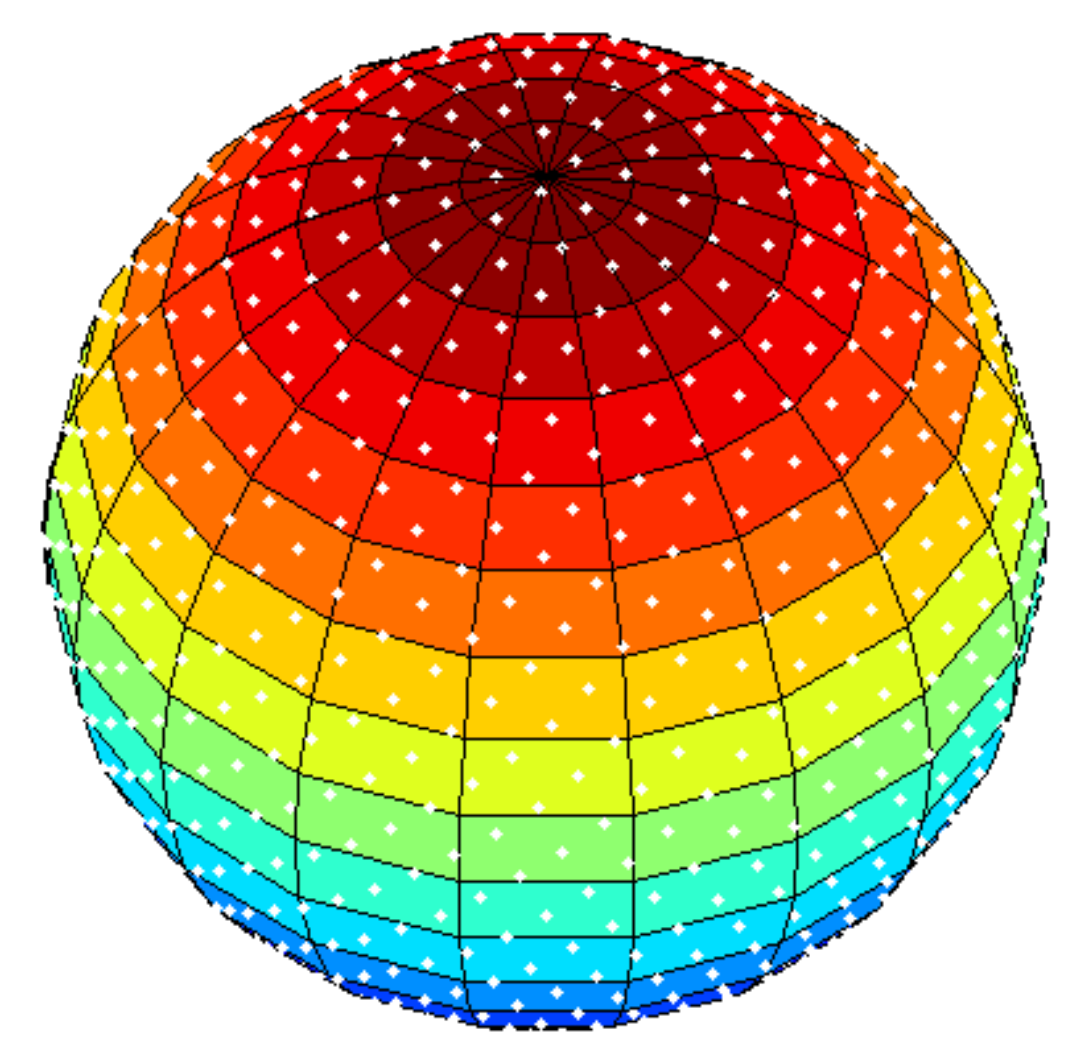
记录如下信息:交点位置,表面法线,Albedo.并存入三张纹理中.
纹理的大小为:采样光线数 * Probe数.
横坐标为每个Probe采样光线数,纵坐标为Probe的Index.
下图为567个Probe进行144次采样的结果.
这三张纹理会被放入一个类似G-Buffe的结构中用于后续计算.
计算Probe Radiance & Distance
使用RayTracing,在RGS(ray gen shader)中发射光线,获取计算小球在各个方向上的radianc和distance.并将结果存入到一张纹理中,用于后续计算.
纹理大小为:ProbeCount * rayCount / ProbeCount.
为了模拟两次以上的间接光照,在计算Probe Radiance时,除了计算碰撞点本身的”直接光照”外,还需要计算其他Probe对这个Probe的影响,即”间接光照”.
在原论文中,每帧每个Probe会计算144个方向,通常认为100-300的区间是合理的.事实上,还可以通过在每帧向不同方向发射光线采样累计,以获得更好的结果.
Probe Blend
这一步使用radiance贴图来更新Probe中的irradiance,使用position体图来更新depth.
使用Radiance贴图更新Irradiance公式如下: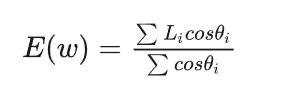
即,将某一方向的半球面上的所有radiance按照cosθ做混合.
使用Position贴图更新Depth于Depth平方公式如下: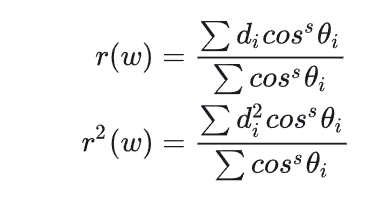
也是对某一方向的半球面上的所有距离按照cosθ^s做混合.
其中θ是纹素方向与采样点方向夹角;s是一个经验数值,用于调整shrpness.s越大,则偏离纹素方向采样点比重越小,一般取50.
八面体映射
DDGI 使用八面体映射的方法打包球面上的数据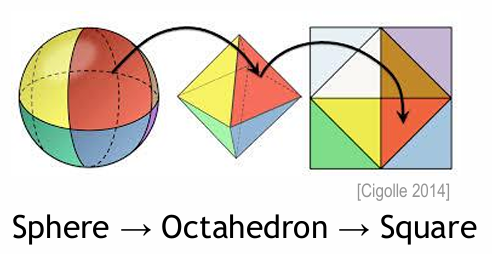
需要注意的是,一些八面体上原本重合的边映射到正方形时被分开了.所以在保存数据时还需要处理纹理的边缘,将被分开的边按反向顺序填入纹理中.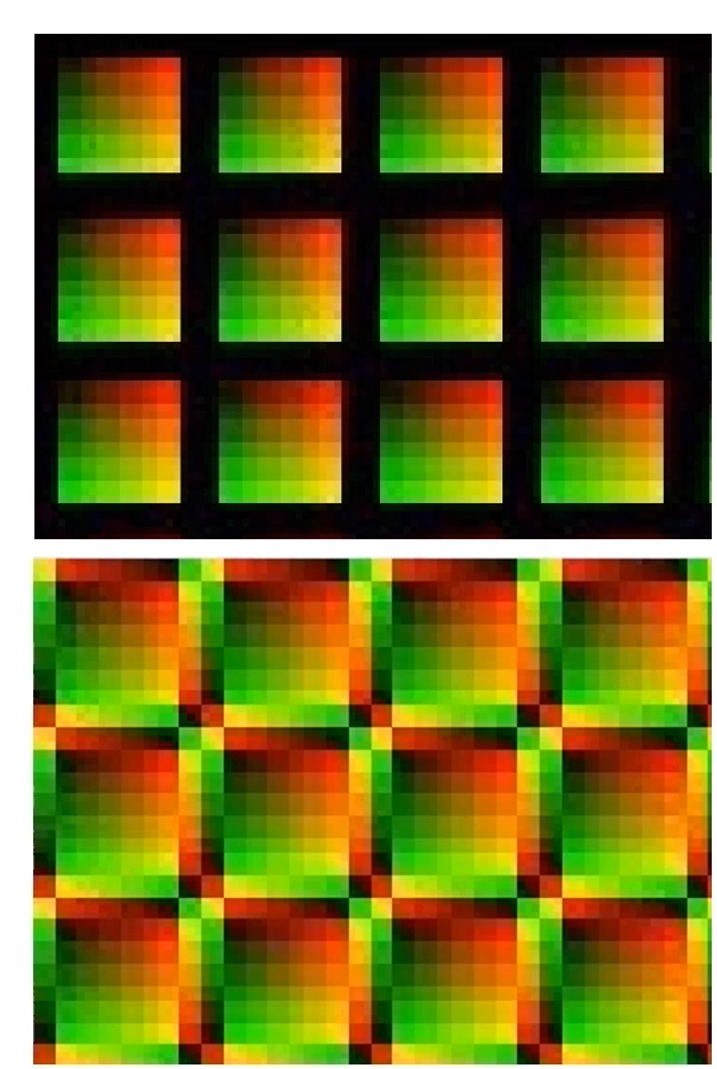
时间超采样
通过降低采样率,复用历史帧采样结果,从而获得更优秀的新能.在使用时间超采样时可以几乎减少一半的采样数.
时间超采样的方式很简单,完成Probe Blend后,将其与上一帧按某种比例进行插值即可.如图: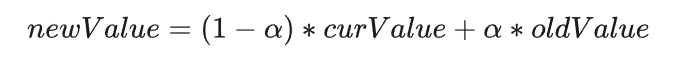
而这个插值参数在Nvdia的实现中为0.97
当然,时间超采样会带来更新迟滞的问题.
但我们也可以进行进一步的优化.
我们希望的是最终结果能够更多地依赖于当前帧和前几帧.而对于更古老的结果,我们希望能够快速忽略,因此可以更改混合算法: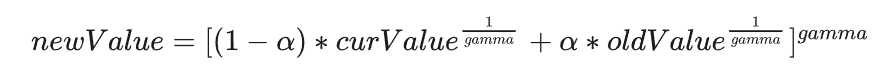
一般gamma取5.0
进一步的优化性能还可以使用分帧更新的方法.
DDGI 优化
在这里会介绍一些DDGI优化的方案.但只会讲解大致思路.
Probe Relocation
DDGI使用切比雪夫测试来剔除可能导致Light Leaking的Probe.但当Probe位置离墙非常近时,也难以避免错误.
而解决方法就是避免Probe位置离墙太近(或者把墙变厚).通过计算并应用一个offset纹理来修正Probe位置防止离墙太近导致错误.
Probe 状态机
并不是所有的Probe都需要每帧更新,比如一些不会接受到光照的物体,一些不会被采样的物体.
因此,我们可以设计维护一个状态机,只更新需要更新的Probe,从而减少计算量.
Volume 移动
当移动DDGI Volume时,我们不能移动所有的Probe,这样会破坏历史帧信息.
可以使用一种类似滑动的方案,即:移动Volume时,只删除移动方向后方的最后一层的Probe,而不改变其他Probe,并在移动方向上增加一层Probe.
Cascaded Volume
Cascaded的思想在工程上过于常用,以至于读者看到这个标题就已经知道什么意思了.所以这里不多做介绍了.
异步GPU光追计算
DDGI 总结
DDGI 利用硬件的求交加速,做到了动态的全局光照,并解决了Light Leaking的问题,最终的渲染结果也十分漂亮.总的来说,是一项未来可期的技术.
由于其Probe的特性,也使得使用DDGI进行渲染时的效率与屏幕分辨率无关.
但DDGI的效率受制于硬件光追的提示,不过好消息是,GPU光追性能提升还算挺快的.
正如名字,DDGI处理的是漫反射项,而为了达到更好的渲染效果,笔者认为可以配合SSGI技术一起使用.
加量不加价,浅析 Lumen
Lumen的大名早已不用介绍.
与其说Lumen是一次里程碑式的科研突破,倒不如说是一个奇迹般的工业神迹.Lumen整合了过往10多年间计算机图形学对全局光照的研究并有机地将他们融合到了一起,还能塞进游戏引擎里,实在是让人叹为观止.
一句话Lumen
屏幕空间放置与计算Probe后与表面shading
Lumen流程
Phase 1:在任何硬件上快速RayTracing
虽然在最新的Lumen中已经增加了对硬件光追的支持,但是光线追踪毕竟是一个非常昂贵的开销,所以在Lumen中为了快速进行RayTracing,首先引入了SDF.
什么是SDF
SDF(Signed Distance Field)是一种基于距离的表示方法,其主要思想是用一个函数来表示物体表面到点p的距离,函数的值越小,则说明p越靠近物体表面.
使用SDF 进行RayTracing
Per-Mesh SDF
在Lumen中,每个mesh都有一个对应的SDF表示,而非对整个场景进行SDF表示.
当场景复杂时,使用Per-Mesh SDF可以显著减少存储.比如一个由100个物体组成的超大场景的SDF大小肯定大于100物体各自的SDF大小和.
在Lumen中实际还解决了这些更细致的问题:
- SDF稀疏化
- SDF LoD
- Global SDF
- Cache Global SDF(Camera-Based Mip Global SDF)
- 等等等等等等….
Phase 2:计算与存储光照
Mesh card
在Lumen中,首先引入了Mesh card的概念.
即对每一个mesh,用正交摄像机拍6张轴对齐”快照”.
通过这样的快照拍摄,可以获得快照的Albedo,Normal,Depth等信息.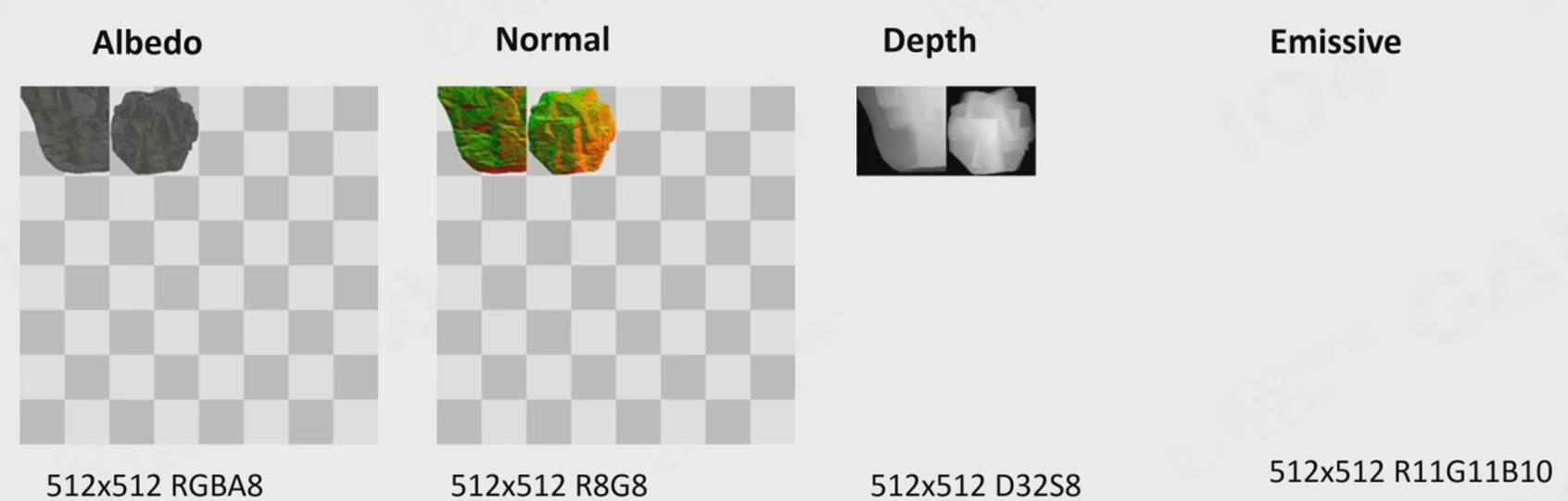
而所有的快照信息会一起存入到一个叫Surface Cache的图集中
而这个Surface Cache就是接下来进行光照计算的数据结构.
计算Surface Cache的光照
计算光照的流程如下: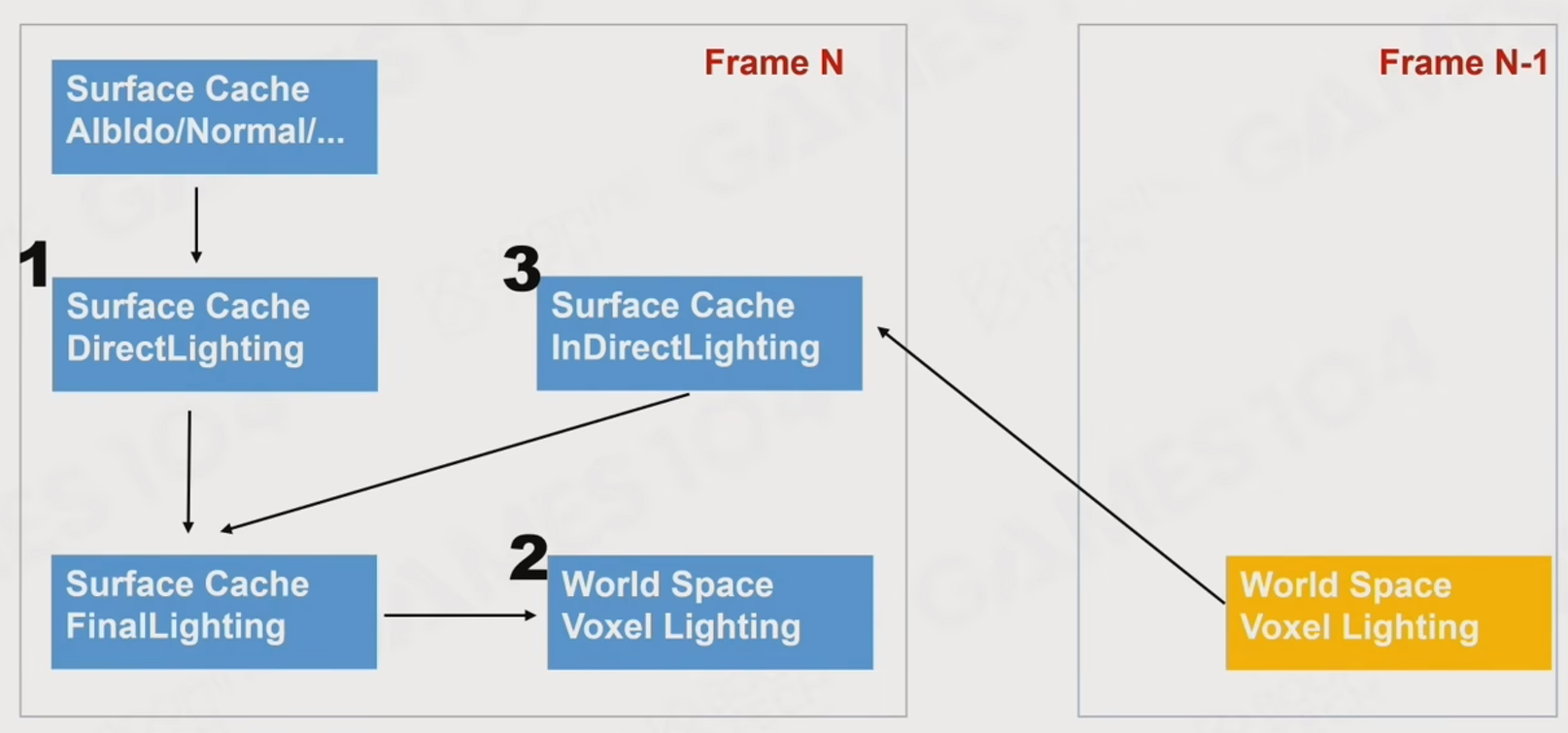
第一步,Surface Cache中的信息,可以计算一次直接光照.这里将结果称为 Surface Direct Lighting.
第二步,获取上一帧的Voxel Lighting在Surface Cache上计算光照,作为间接光照.这里将结果称为 Surface Indirect Lighting.
这里先别管Voxel Lighting是怎么来的,后面会说到.
第三步,通过Surface Direct Lighting和Surface Indirect Lighting,计算出Surface Cache的最终光照.这里将结果称为 Surface FinalLighting.
第四步,将得到的Surface FinalLighting计算Voxel Lighting,供下一帧使用.
值得注意的是,这里的Voxel Lighting实际上存储的并不是像Voxel GI 或 Probe那样的光照信息,而更像是”被照亮”的信息.甚至可以理解为像是一块3D化的马赛克贴图.正如这张图所示:
而Lumen用到Probe(World Space)的地方是在计算Indirect Lighting时.而计算Probe要如何获取场景的信息来计算自己的函数呢?在DDGI中是与场景求交,而在Lumen中则是与”打码”后的场景求交.并将信息存入球谐函数中.
这里也可以不负责任的认为Lumen是对DDGI的进一步发展(主要是文章标题是关于DDGI的).
Lumen计算全局光照比DDGI更近一步.回顾DDGI的两大核心:光追与Probe.其中最为耗时的运算就是光追步骤.
Lumen说:传统光追还是太慢了,所以Lumen用SDF来加速光追.
Lumen说:DDGI光追和精细场景求交.拜托,本身你就是低频信息,干脆直接和低频的场景求交不是更快?
嗯,Lumen的确是对DDGI的进一步优化( ^ω^)
事实上,确实有使用SDF来进行加速的DDGI方案
哼,我就说Lumen是DDGI++++
Phase 3:I need Probes,a lots of Probes.
Screec Space Probe
传统的Probe有一个问题,正如DDGI的优化策略中的Probe 状态机一样,事实上有很多Probe很少被用到.
而Lumen选择直接在屏幕空间撒Probe,而非在场景中撒,这不就每个Probe都很有用了吗?
而在计算Screen Space Probe时,又用到了World Space Probe.这其中更细致的问题就不在解释了,太多了.
在Lumen中实际还解决了这些更细致的问题:
- Refine Screen Space Probe(adaptive screen space probe sampling)
- Screen Probe Atlas
- Screen Probe Jitter
- Importance Sampling
- Connecting rays
- 等等等等等等….
Phase 4: Shading With Screen Space Probes
Lumen 总结
Lumen的核心之一就是:如何快速做RayTracing.
在这一问题上,Lumen使用了一个三段式的解决方法.

- 首先和HZB(High Z-buffer)求交
- 1.8m内与Mesh SDF求交
- 1.8m外与Global SDF求交
Lumen另外核心在于:
- 场景的简化表达
- 基于Screen Space Probed GI求解
Lumen实乃工业神迹.
参考
Games101
Games202
Games104
NV DDGI
DDGI论文
剑网3的DDGI使用
DDGI优化
NV大佬DDGI博客
DDGI相关博客
DDGI相关知乎
Jiff 的Lumen博客
RealTimeRendering4th-CN
RSM
LPV
ISM
VXGI-知乎
DXR-知乎大佬
斐波那契螺旋采样
 wechat
wechat alipay
alipay